Enhancing an Existing LLM Model with Domain-specific Jenkins Knowledge

![]()
About the Project
JenAI is a pioneering chatbot that is trained specifically to answer users' queries about Jenkins technology, which enhances the accessibility and usability of software.
We aim to provide faster and more reliable assistance to our users. The model is integrated with a friendly UI to ensure a better user experience.
The project outcomes are:
-
Collected datasets from different sources, like Jenkins blogs, community questions, and other external sources.
-
Preprocessing this dataset to make sure it is clean and not confusing the model.
-
Fine-tuning llama2 on this data and providing a new open-source fine-tuned model.
-
Creating a user interface with a small server to interact with the model.
-
Providing documentation of all the work done and a user guide to use our chatbot locally on your machine.
Why JenAI:
-
Jenkins currently does not have AI-driven assistive technology to help new Jenkins users.
-
This project combines Jenkins knowledge with AI to assist all users with the knowledge that a Jenkins expert usually has, providing a complete solution.
-
We empower users to interact with this knowledge through a smooth UI instead of looking for your answer here and there.
Milestones
This project included several stages that we have gone through:
Stage #1: data collection
Different sources were used to collect Jenkins knowledge, including Jenkins documentation and blog posts, discourse community questions, and many external sources like Stack Overflow, ask Ubuntu, and Stack Exchange.
Stage #2: data preprocessing and refinement
This stage consisted of 3 parts:
-
The first part is utilizing another large language model to help us generate question-answer pairs out of Jenkins documentation.
-
The second part is using Stack Exchange queries to get datasets of questions and correct solutions asked on Stack Overflow and many other platforms. We could define a score threshold for those questions and answers to ensure the reliability of the dataset we are collecting. The dataset generated includes HTML tags like paragraph code and many un-useful blocks or urls, so further processing was done to remove all useless information.
-
The last part of this is utilizing the community questions available on Discourse, where we could use discourse apis to prune Jenkins posts and retrieve ones with approved solutions, then we could do another request to retrieve those posts and their answers.
All those parts are automated, and the notebooks for creating the datasets are provided on our repository. In doing so, we managed to collect around 4100 pairs; a bunch of which were used to fine-tune our model on.
Stage #3: JenAI as a system
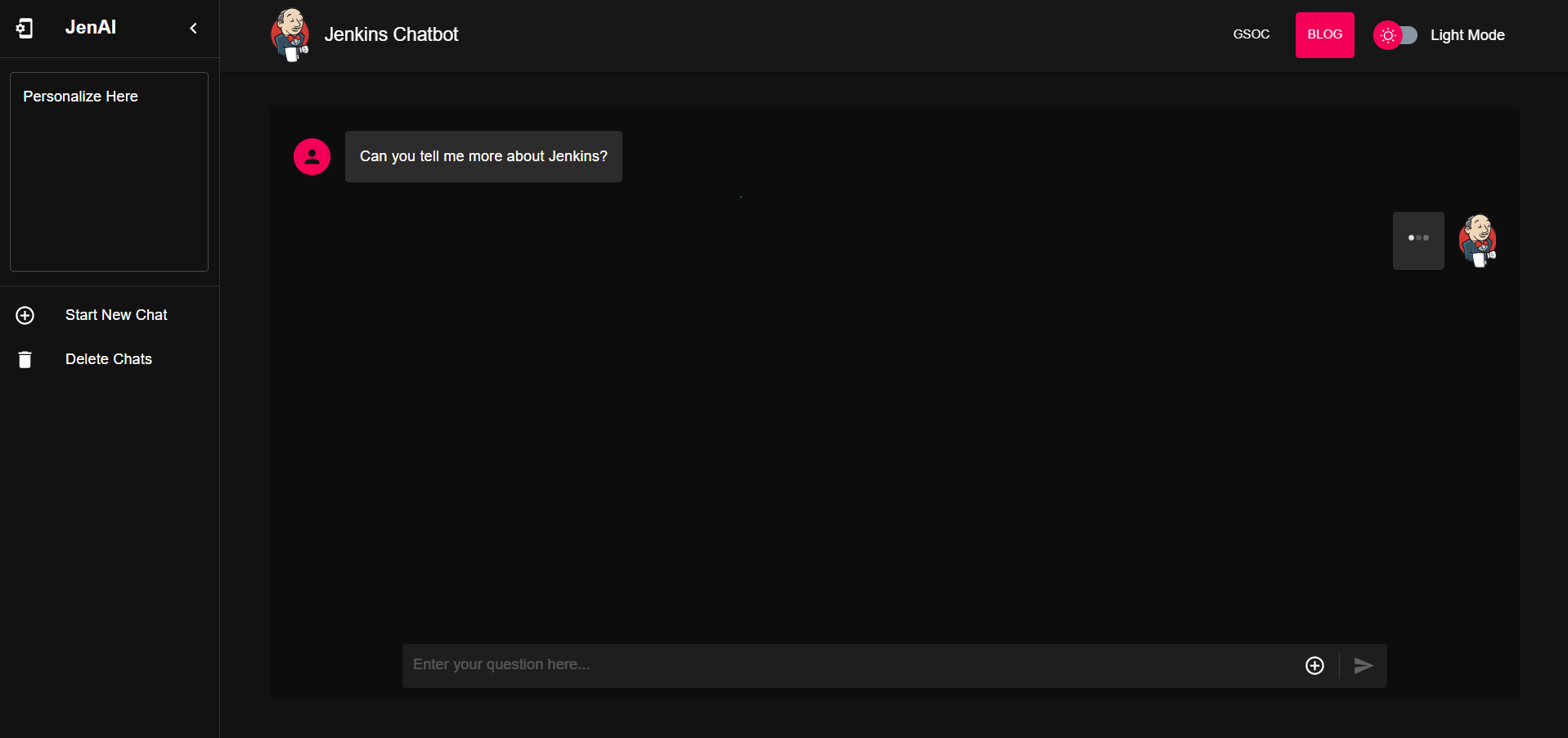
This stage was about creating software with a friendly user interface as part of this project to interact with the model. We used ReactJS, Typescript, and MUI components to help us create the interface.
We also used Flask to create a small server with only one endpoint (so far) to interact with the model through Rest API and ensure smooth communication.
Stage #4: Fine-tuning
The core of our project, the effort of fine-tuning, was iterative and repeated until we made sure of its performance. A lot of research is conducted here to ensure the optimal parameters and the best approach to fine-tuning the model and obtaining accurate results.
We were using Colab and Kaggle free resources to fine-tune our model as they provide a T4 GPU with around 16 gigabytes of VRAM, which is powerful enough to load and fine-tune our model.
Details of fine-tuning, the approach, and parameters are provided in our Final Documentation.
Stage #5: Convert the model to GGML format and quantization
In order to achieve our objective, we need users to be able to run the model on their local machines using only CPUs instead of hosting it. To achieve this, we used llama.cpp to convert the model to a GGML binary format (using convert_hf_to_gguf.py) that can be loaded and run on CPU.
Part of the appeal of the GGML library is being able to quantize this binary model into smaller models that can be run even faster. There is a tool called quantize in the Llama.cpp repo that can be used to convert the model to different quantization levels. We used the quantize tool to shrink our model to q8_0.
Next Steps
This idea can be enhanced more, and many approaches are provided to achieve the same goal:
-
Using retrieval-augmented generation (RAG) that combines the strengths of databases or traditional information retrieval systems with the capabilities of large language models.
-
Llama3 that has been pre-trained on over 15 trillion tokens, with a dataset used in training 7 times larger than the one used for training Llama2, which can make it outperform Llama2 when fine-tuning on Jenkins knowledge.
Acknowledgments
I want to take this chance and extend my gratitude to:
-
Google Summer of Code for organizing this and their mentors who provided help throughout the program.
-
Jenkins and GSoC org admins for having me contribute to this challenging problem and thank you for your flexibility along the way.
-
My team mentors Kris Stern(as a lead mentor), Bruno Verachten, Harsh Pratap Singh, and Shivay Lamba for their continuous support and guidance throughout the project, answering my questions, and pointing out some great ideas so we are not left with something incomplete. They were a great reason for making this a success.
About the author